

Читайте новини і аналітику про ритейл та e-commerce в Україні на нашій сторінці в Facebook, на нашому каналі в Telegram, а також підписуйтеся на щотижневу e-mail розсилку.
Как в Uklon работает модель ценообразования с использованием машинного обучения
Itc
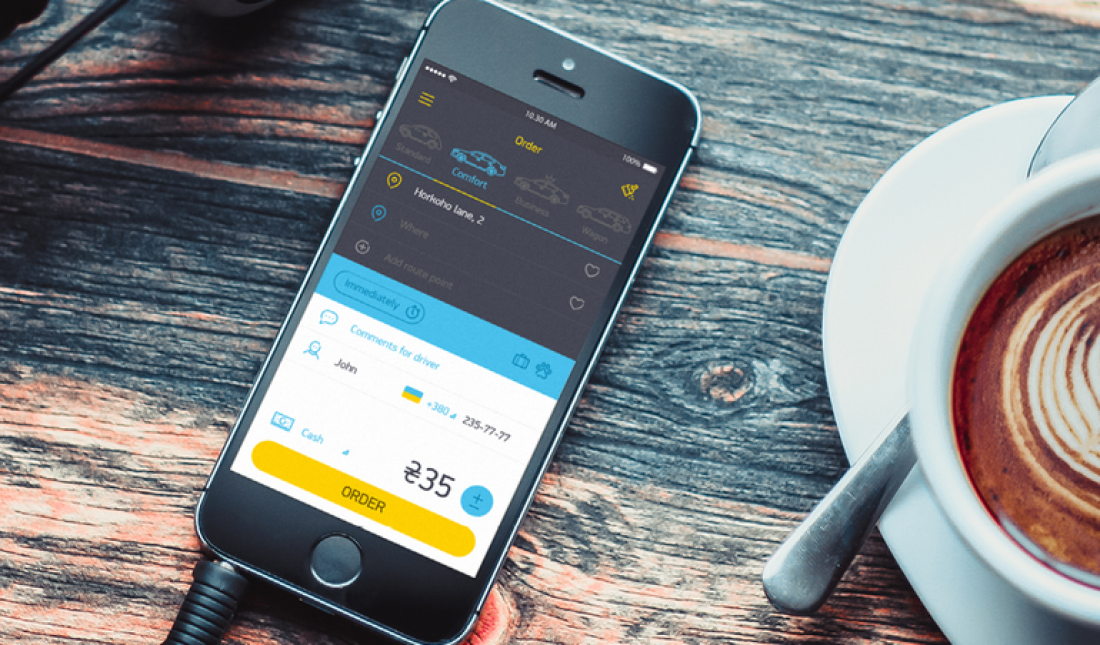
Найти авто по загруженным маршрутам бывает тяжело, и тогда клиентам приходится повышать тариф. Это отнимает время и требует точного знания, за какую наценку приедет водитель. Чтобы сократить время прибытия авто, компания SMART business с помощью предиктивной аналитики разработала алгоритм, который по предыдущим заказам автоматически высчитывает, на сколько нужно поднять сумму. Такую модель уже тестируют в Uklon, и в 75% заказов клиенты не торгуясь соглашаются со стоимостью, которую предложит модель.
Один из разработчиков модели — Дмитрий Солопов — рассказал о создании услуги, о том, чем она отличается от простого динамического ценообразования и как использует для работы географию местности и историю заказов
— Откуда возникла идея создать услугу, которая будет генерировать наценку на поездку, чтобы уменьшить время прибытия авто? Uklon сам предложил вам такой проект?
— SMART business как раз начали развивать направление Data Analytics, а партнеры Uklon, Microsoft, обратились к нам и предложили поработать над моделью с платформой Microsoft Azure Machine Learning. Система работает на мощности этой платформы. Таким образом, Microsoft предоставил платформу и посоветовал специалистов, а мы выполняли проект.
— С чего обычно начинается разработка такого проекта?
— Совместно с Uklon мы решили улучшить 2 показателя: «время прибытия » и «процент выполнения заказов». На эти два показателя могут влиять много параметров: цена, конечная точка маршрута, марка машины, место прибытия, время суток, время года. Поэтому мы набрали определенный ряд таких параметров и начали проверять эти гипотезы на данных Uklon в Киеве.
В основе алгоритма используются данные по прошлым поездкам: маршруты, время поездок, кто клиент и как часто он ездит, соглашается ли на торг и отменял ли заказ. По этому поведению клиенты сгруппированы по сегментам и построена поведенческая модель пассажиров.
— Какие гипотезы вы тестировали и как работали с параметрами?
— Два параметра для прогноза — это география и время. Сначала мы анализировали места подачи машины, а также точки возникновения спроса в разных районах Киева, и разбили город на кластеры, которые отличались от стандартного разделения города на административные районы. Второй параметр — это время заказа, которое мы также агрегировали по группам, чтобы выделить сезоны, дни недели и время в сутках, когда возникает наибольший спрос. Таким образом, образовались временные группы, с которыми дальше было легче работать для формирования цены.
Фото: SMART business.
Пример отображения на карте города центров кластеров, сформированных с использованием нескольких параметров
Мы вносим внешние данные постоянно, так как модель нужно все время переобучать.
— Как вы использовали собранные данные в разработке?
— Чтобы мы смогли проверить гипотезы, Uklon предоставил нам свои внутренние данные: таблицу по прошлым заказам и поездкам клиентов. По размеру она была около 20 Гб, каждая запись в ней характеризовалась 20 разными параметрами, которые во время изучения пополнялись информацией о водителе, автомобиле и клиенте. Также мы руководствовались данными, полученными из открытых источников: информацией о погоде с сайтов, открытыми данными от NASA и с метеостанций трех киевских аэропортов.
Мы смогли сделать модель такой, чтобы она понимала, в какой момент нужно поднять цену и на сколько. Модель просчитывает оптимальную цену для данной поездки, при которой пассажир не будет торговаться в часы пик.
—Сколько вы потратили времени на разработку?
— Проект занял 5 месяцев. Все данные и гипотезы для модели мы собрали и проверили за полтора месяца, остальное время ее тестировали и интегрировали. В Uklon ее внедрили для использования в сервисе.
— У Uklon есть еще одна модель ценообразования. Расскажите о ней, чем она отличается от новой?
— До недавнего времени онлайн-сервис Uklon использовал ценообразование на основе динамического коэффициента, который учитывает только два фактора — уровень спроса (количество запросов на подачу машины) и количество доступных к заказу машин.
По этой модели стоимость заказа в моменты высокого спроса подсчитывалась по количеству километров на маршруте, далее применялся динамический коэффициент. Предполагалось, что он сформирует цену, оптимальную для того, чтобы увеличить шансы приезда машины. При этой модели существовала одна проблема – в некоторых точках города процент вывоза клиентов был низким. Заказчики не могли вызвать авто долгое время и таким образом мы теряли клиента.
Сейчас же – в период тестирования – две модели ценообразования работают вместе. Половина заказов приходится на старую, другая половина — на новую модель. Это нормальное явление, когда тестируют две разные модели. Может появиться еще одна новая модель, потому что она будет лучше.
— Чем предиктивная аналитика отличается от обычной аналитики по географии?
— Обычная описывает, что и почему произошло, а предиктивная принимает и автоматизирует решение — предлагает торг и цену. Модель учится на том, как вы ездите, и самостоятельно поднимает цену. Все клиенты ее обучают. Если клиент утром в 9 утра уедет на работу, то модель на этом количестве поездок наберет данные и научится выставлять соответственную цену. А динамический коэффициент не учитывает историю.
— Насколько было трудно разработать эту модель?
— Над этим проектом занималась небольшая команда: технические специалисты из Microsoft, которые давали консультации касательно использования технологий, собственно команда Data Science инженеров компании SMART business, которые разрабатывали и проверяли гипотезы, создавали и тренировали модель, и специалисты Uklon, которые предоставили информацию по бизнес-процессам компании и исторические данные для построения модели.
Фото: SMART business.
Пример построения модели в Azure Machine Learning Studio
Хотя над моделью работали опытные инженеры, бывает, что гипотезы неверны. Если гипотеза не подтверждается, то обычно мы проверяем все ли данные собраны, их качество. Некоторые данные собрать сложно. Также я бы выделил то, что модели нужна определенная донастройка по работе с данными и заказами за город. Сейчас алгоритм модели работает на основе тех данных, на которых она обучалась, но в дальнейшем планируется переобучение модели каждый месяц или даже каждую неделю с учетом новых данных.
— Эта модель пока активна только в одном городе? Какие планы на другие города?
— Эта модель работает только в Киеве. Чтобы масштабировать систему в новом городе, нужно снова сделать систему кластеров по времени загруженности и наложить ее на географию нового города.
— Какие результаты работы модели?
Благодаря новой модели показатели выполнения заказов и времени ожидания улучшились, то есть изначальные цели нашего проекта выполнены. Мы смогли улучшить эти показатели на 5–15% по сравнению с прошлой моделью ценообразования. Теперь водитель забирает заказ на 18 секунд быстрее. Для примера, если взять пул в 3000 заказов, получается экономия около 15 часов. А если считать в год, то средняя семья с 4 поездками в неделю, сэкономит 1 час в год. Помимо того, увеличились продажи и средний чек поездки, при этом количество клиентов не сократилось.
— Сколько стоит разработать такую систему?
— Стоимость проекта была менее $10 000. Для нас это был имиджевый проект, ведь SMART business выходил на рынокпродвинутой аналитики и решил показать свои возможности. Мы можем сказать, что этот проект коммерчески успешен.
— Какие еще проекты будете разрабатывать в партнерстве с Uklon?
— В будущем мы планируем обучать модель за счет данных с сайтов, где публикуют информацию о мероприятиях в городе, таких как кино, спортивные матчи, выставки, концерты. Таким образом, можно спрогнозировать возможное повышение спроса в определенных кластерах города.
Помимо этого, мы работаем над новым чат-ботом, который будет выполнять роль персонального помощника. Например, на случай если вы забыли сумку в машине. Natural Language Processing (NLP) может использовать NLP-алгоритмы для ваших вводимых сообщений и, анализируя жалобы, понять, почему клиент ушел от Uklon. Общий запрос на машинное обучение есть, использованием machine learning алгоритмов уже интересуются топ-10 ритейлеров из офлайн- и онлайн-пространств.
— Как можно применять технологии машинного обучения в ритейле?
— Как за рубежом, так и в Украине, эта технология уже используется для решения различных бизнес-задач ритейла, например: поиск оптимальных мест для открытия торговых точек, формирование персонализированныхпредложений, анализ поведения покупателя и оптимизация стоимости. Еще одно разработанное нами решение для ритейла с использованием машинного обучения – SMARTDemandForecasting – позволяет более точно прогнозировать спрос и объемы продаж в розничной сети по каждой торговой точке, благодаря чему в каждом из магазинов всегда находится оптимальное количество товаров и покупатель не будет сталкиваться с ситуацией, когда интересующий его товар отсутствует на полке магазина, таким образом ритейлер не будет терять своего клиента. Также это решение поможет оптимально спланировать производство и закупки, сэкономить на складских и логистических затратах.
Другой пример использования машинного интеллекта, уже в связке с видео- или фото-фиксацией в магазине, позволяет распознавать посетителей – кто впервые пришел, кто существующий клиент, а кто еще не покупал ничего, но пришел повторно – и давать руководства к действию для продавцов или предоставлять аналитику для руководителей.

Пример аналитического дашборда по посещаемости торговых точек
По данным Keystone Strategy 2016, компании, которые проводят такую «цифровую трансформацию», анализируя большие данные, используя облачные сервисы и задействуя искусственный интеллект для оптимизации процессов, могут вдвое увеличить свой операционный доход и на 50% чистую прибыль
Автор: Валерия Дорош